
Google Compute Engineの可用性機能を体験した #gcpja
ども、takiponeです。
Google Compute Engine(GCE)のVMインスタンスには、2つの可用性ポリシーが既定で有効になっています。先日、本ブログをホストしているVMインスタンスで可用性機能による再起動およびライブマイグレーションが実行されたのでその様子と解説をレポートしてみます。
設定と動作ログ
Developer Consoleの設定画面は以下の通りです。可用性ポリシーとして、[自動再起動]と[ホスト メンテナンス時]の2つがあります。
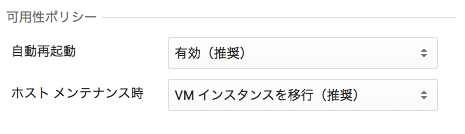
既定で両方とも有効になっていますね。実際にこれらの設定により動作したログが以下になります。

これは、Developer Consoleのメニューから[オペレーション]で表示される動作ログ一覧の一部です。今回は移行が8/15 4:49、再起動が8/15 4:58に動作したことがわかります(一覧の時刻表記はロケールに対応しているようで、日本時間でした)。
早朝だったため動作時に出くわすことはできませんでしたが、その日の夕方に気づき、インスタンスにはSSH接続できることを確認しました。正常に再起動が動作していたようです。
ここからは、設定についての解説と考察を示します。
可用性ポリシー
自動再起動
[自動再起動]は[有効]に設定することで、VMインスタンスを実行する物理ホストのハードウェア/ソフトウェア障害時に、別の物理ホストでVMインスタンスを再起動する設定です。障害時には物理ホストの変更とVMインスタンスの起動のために、短時間のダウンタイムが発生します。
通常時

物理ホスト障害時
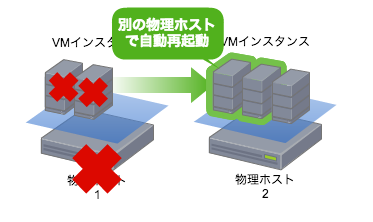
VMwareで言うとvShere HAに相当する機能です。vSphere HAでは物理ホストもユーザーが管理する必要があったため、**「どの物理ホストからどの物理ホストに移るのか、どのVMから優先して再起動を行うのか」**などを考慮する必要がありそれなりに管理コストのかかる機能でした。しかし、GCEでは物理ホストの管理をGoogleが行うため、ユーザーは「再起動してほしいのか、しないで欲しいのか」のみを判断するだけで手軽に利用できます。
ホストメンテナンス時の移行
[VMインスタンスを移行]という設定は、いわゆるライブマイグレーションを指します。Googleが物理ホストの計画メンテナンスを行うために、VMインスタンスを他の物理ホストにVMインスタンスを実行したままで移動します。自動再起動とは異なり、VMインスタンスにダウンタイムは発生しません。VMware vSphereで言うと、vMotionに相当する機能です。

ライブマイグレーションはメモリなどVMインスタンスの状態情報を物理ホスト間でコピーするため、移行中は一時的にVMインスタンスのパフォーマンスが低下するとドキュメントに記載がありますが、文中でも触れられてるように、一般的なサーバー用途では大きな影響はなさそうです。RightScaleによる検証記事もあります。
考察
自動再起動とライブマイグレーションは、どちらも仮想化プラットフォームでは既に確立された技術ですが、超大規模なIaaS環境で標準機能として提供するのは技術的にもサービス的にもそれなりに敷居が高いことが想像できます。実際、どちらの機能もAmazon EC2では現在提供されていません。EC2の運用で必須となるメンテナンス告知に対応するインスタンスのStop-Startは、ユーザーにそれなりの負担がかかるため、Googleの運用側でメンテナンス対応の面倒を見てもらえるのはかなり嬉しいです。
また、Amazon RDSやAmazon ElastiCacheなどの多くの"as a Service"形態のサービスとGCEのVMインスタンスにDBやKVSをインストールする構成を比較することもできると思います。もちろんAWSの各サービスには運用をサポートする機能がありますが、可用性確保のための運用コストはGCEの可用性機能でカバーできると考えて、「GCEにはElastiCache相当のサービスが無いから却下」や「CloudSQLはMySQLしかないし、Privateネットワーク内に通信を閉じられないから却下」ではなく、構成が出来上がっているAWSのサービスと自由に構成できるGCEのVMインスタンスで比較検討するのはどうかなー?と思っています。

