
Google Compute Engineのロードバランサを読み解く#1 #gcpja
ども、takiponeです。
GCE(Google Compute Engine)でVMインスタンスと並んで注目される機能が、ロードバランサ(負荷分散)だと思います。今回から数回に渡ってロードバランサを触り、その特徴をまとめてみたいと思います。
GCEロードバランサの基本
GCEのロードバランサは、2つの独立したサービスがあります。
-
Network load balancing (L4ロードバランサ)
-
HTTP load balancing (L7ロードバランサ)[Limited Preview]
-
参考 : Google佐藤さんのQiitaでの紹介
今回は、L4ロードバランサを提供するNetwork Load Balancingを試してみます。
VMインスタンスの準備
まずは、実際に作成して動作を確認します。今回はこちらのエントリーでご紹介した自動構成を利用し、ロードバランサの転送先としてWebサーバーのVMインスタンスをeast-asia1リージョンに2台作成しました。
スクリプト例 : gce-startup-asia1.sh
#! /bin/bash
# Installs apache and a custom homepage
apt-get update
apt-get install -y apache2
cat <<EOF > /var/www/index.html
<html><body><h1>Hello asia1</h1>
<p>This page was created from a simple startup script!</p>
</body></html>
EOF
上記スクリプトをgcutil addinstanceコマンドのオプションで指定し、VMインスタンスを起動します。
$ gcutil addinstance web-asia1 \
--auto_delete_boot_disk \
--metadata_from_file=startup-script:gce-startup-asia1.sh
:
$ gcutil addinstance web-asia2 \
--auto_delete_boot_disk \
--metadata_from_file=startup-script:gce-startup-asia2.sh
:
試しにWebブラウザからアクセスしてみます。
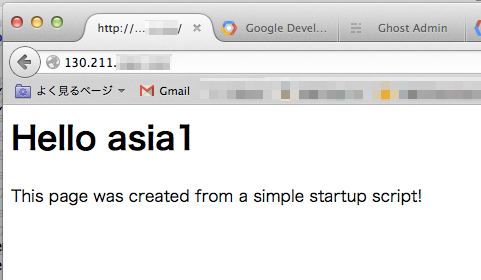
Apacheが動作し、正常にWebページが表示されることを確認できました。
ロードバランサの定義
続いて、VMインスタンス2台にHTTPトラフィックを転送するロードバランサを定義します。GCEのNetwork Load Balancingは、厳密には以下の3つの設定を組み合わせて定義します。
- 転送ルール
- ターゲットプール
- ヘルスチェック
Developer Consoleの[ネットワークの負荷分散]メニューでは、簡単に設定するために1画面でウィザードライクに一括設定できるようになっています。Network Load Balancingはリージョンにひもづくため、まずは地域(リージョン)を選択し、名前の接頭辞(このあとの各設定の先頭文字列)を入力します。
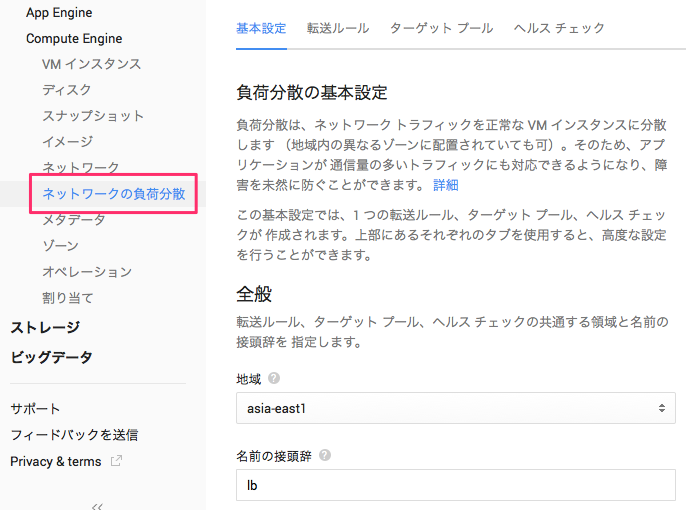
転送ルールとして、ロードバランサのエンドポイントとなる外部IPの種類を選択します。エフェメラルは、ルールを削除すると解放される一時的なものです。静的IPをあらかじめ取得しておき、それをここで選択することで外部IPを固定することもできます。また、静的IPはVMインスタンス用と区別しないため、VMインスタンスからロードバランサに付け替えることで外部IPを変更せずに"VMインスタンスへの直接アクセス"から"ロードバランサ経由のアクセス"への切り換えもスムーズにできます。
プロトコル/ポートでは、ロードバランサがVMインスタンスに転送するプロトコル(TCPもしくはUDP)およびポート番号を指定します(デフォルトではTCP/80)。
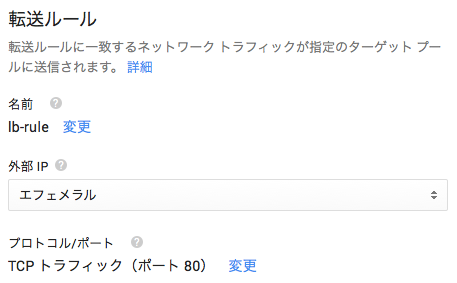
ターゲットプールは、ロードバランサが転送するVMインスタンスをグループ化する単位です。複数のゾーンのVMインスタンスを選択することで、ゾーン(データセンター)障害にも対応できる構成とみなすことができます。
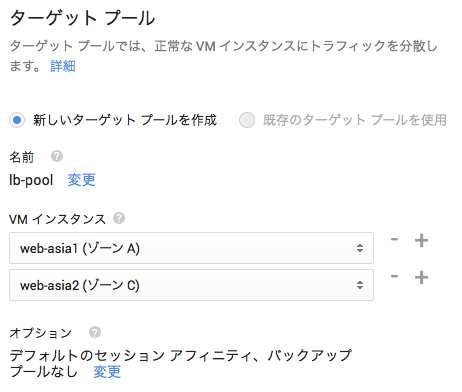
ヘルスチェックは、ロードバランサがVMインスタンスの健全性を確認する設定です。デフォルトでは、5秒に1回パス/にHTTPアクセスを試行します。200レスポンスが2回以上返れば健全と判断し、トラフィックを転送します。
一通り設定を入力したら、[作成]ボタンをクリックして作成します。
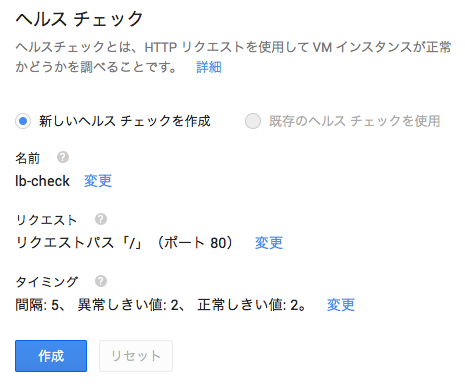
すると、自動的に転送ルール一覧に画面が切り替わります。
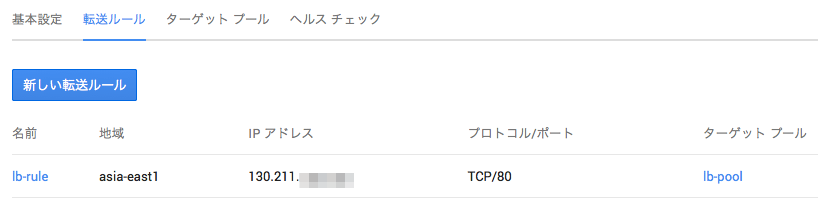
転送ルールlb-ruleができました!早速Webブラウザからロードバランサの外部IPにアクセスしてみます。
Webページが表示されました!ロードバランサは正常に動作しているようです。少し時間を置いてリロードすると、もう1台のVMインスタンスのレスポンスもときどき返ってきます。
では、ここからはロードバランサの動作を少し細かく見て行きます。
分散アルゴリズム
Network Load BalancingがどのVMインスタンスにトラフィックを転送するかは、以下5つの項目でロードバランサが評価し分散するようになっています。
- 通信プロトコル
- クライアントのIPアドレス
- クライアントのポート番号
- ロードバランサのIPアドレス
- ロードバランサのポート番号
HTTP通信の場合は、1,4,5は一定ですので2,3による分散が期待できます。この動作はセッションアフィニティ設定で調節することができます。
- セッションアフィニティ
- なし (デフォルト)
- クライアントIP (2,4のみ)
- クライアントIPとプロトコル (1,2,4のみ)
これらの設定により、同じクライアントからの接続は、毎回同じVMインスタンスに固定するといった動きが期待できます。しかし、クライアント側でNATを構成していると、クライアントIPがNAT配下の全てのクライアントで同一になってしまい、同一VMインスタンスに転送されてしまうリスクも理解しておく必要があるでしょう。
ハートビート
ハートビートはNetwork Load Balancingの場合、メタデータサーバー(169.254.169.254)から送信されます。以下にHTTP:80、パス/の場合のVMインスタンス側のApacheアクセスログを示します。
$ sudo tail /var/log/apache2/access.log
169.254.169.254 - - [26/Aug/2014:00:11:08 +0000] "GET / HTTP/1.1" 200 390 "-" "-"
169.254.169.254 - - [26/Aug/2014:00:11:13 +0000] "GET / HTTP/1.1" 200 390 "-" "-"
:
$
VMインスタンスではハードビートを受信できるよう、ファイヤーウォールを設定しておく必要があります。ただ、後述の理由から転送するポートは多くの場合任意のホスト(0.0.0.0/0)からの接続を許可することになるため、ハートビート用と意識する必要は概ね無いと考えて構いません。
Network Load BalancingはDSR型
L4ロードバランサは、一般にIPヘッダを書き換えるNAT型と書き換えないDSR(Direct Server Return)型に分類できますが、Network Load BalancinはDSR型です。
VMインスタンスでtcpdumpを実行してみると確かに送信元IPアドレスはクライアントのIP、宛先IPアドレスはロードバランサの外部IPになっており、アドレスは書き換えられていないことがわかります。
tcpdumpコマンドの実行結果の例(1.1.1.1がクライアントIP、2.2.2.2がロードバランサの外部IP)
00:19:04.307390 IP 1.1.1.1.21679 > 2.2.2.2.80: Flags [S], seq 46207921, win 14600, options [mss 1460,sackOK,TS val 1087899376 ecr 0,nop,wscale 3], length 0
00:19:04.307449 IP 2.2.2.2.80 > 1.1.1.1.21679: Flags [S.], seq 409901167, ack 46207922, win 28160, options [mss 1420,sackOK,TS val 370367 ecr 1087899376,nop,wscale 7], length 0
00:19:04.343710 IP 1.1.1.1.21679 > 2.2.2.2.80: Flags [.], ack 1, win 1825, options [nop,nop,TS val 1087899413 ecr 370367], length 0
00:19:04.343721 IP 1.1.1.1.21679 > 2.2.2.2.80: Flags [P.], seq 1:425, ack 1, win 1825, options [nop,nop,TS val 1087899413 ecr 370367], length 424
このため、VMインスタンスのファイヤーウォール機能ではロードバランサからのトラフィックを区別することができません。公開サービスでNetwork Load Balancingを利用する場合、ファイヤーウォールでは任意のホスト(0.0.0.0/0)に対してサービスで使用するポートの接続を許可する必要があります。
また、OSのデフォルトのネットワーク設定では自ホストのIPアドレスと異なるアドレス宛のトラフィックは受信しないため、DSR型ロードバランサを利用する場合は一般にiptablesなどでロードバランサの仮想IPを受信する設定を追加します。ぱっと見、VMインスタンスにはそのような設定が見当たらなかったのですが、システムログ(/var/log/messages)を眺めるとそれらしいログがありました。
$ sudo view /var/log/messages
Aug 26 00:09:38 web-asia1 google-address-manager: INFO Changing public IPs from None to ['130.211.XXX.XXX'] by adding ['130.211.XXX.XXX'] and removing None
google-address-managerとは何ぞや?ということでプロセスを探ってみました。
$ ps ax | grep google
1791 ? S 0:01 /usr/bin/python /usr/share/google/google_daemon/manage_addresses.py
1971 ? Ss 0:00 startpar -f -- google-accounts-manager
1974 ? S 0:00 /usr/bin/python /usr/share/google/google_daemon/manage_accounts.py --daemon
6705 ? S 0:00 /usr/bin/python /usr/share/google/google_daemon/manage_accounts.py --daemon
6720 pts/1 S+ 0:00 grep google
$
/usr/share/google/google_daemon/manage_addresses.pyがそれらしい感じですね。中身を見てみると、同じディレクトリのaddress_manager.pyを読み込んでいるようで、こちらにルーティングテーブルを追加する処理(141行目)がありました。
/usr/share/google/google_daemon/address_manager.py
139 def AddOneAddress(self, addr):
140 """Configure one address on eth0."""
141 cmd = '/sbin/ip route add to local %s/32 dev eth0 proto %d' % (
142 addr, GOOGLE_PROTO_ID)
143 result = self.system.RunCommand(cmd.split())
144 self.IPCommandFailed(result, cmd) # Ignore return code
なお、google-address-managerはGitHubで公開されています。
ここでの設定の結果は、以下の/sbin/ipコマンドで確認できます。(5行目、130.211.XXX.XXX宛を自ホスト宛とする設定)
$ /sbin/ip route list table local
broadcast 127.0.0.0 dev lo proto kernel scope link src 127.0.0.1
local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
broadcast 127.255.255.255 dev lo proto kernel scope link src 127.0.0.1
local 130.211.XXX.XXX dev eth0 proto 66 scope host
local 172.16.11.15 dev eth0 proto kernel scope host src 172.16.11.15
broadcast 172.16.11.15 dev eth0 proto kernel scope link src 172.16.11.15
$
また、帰りのルーティングはこちらのエントリーで解説した通り、必ずゲートウェイを経由するためその先(ゲートウェイとロードバランサの間)でうまいこと整合性を持たせていると考えられます。
Amazon ELBとの違い
ここまでの内容を踏まえ、よく比較されるであろうAWSのロードバランササービスであるELB(Elastic Load Balancing)との違いを示してみます。
HTTP Load Balancingとの比較ではないことに注意してください。
仕組み
ELBはL7ロードバランサ(L4に切り換えることもできます)ですので、L4のNetwork Load Balancingとは仕組みによる機能差があります。
上述の仕組みの違いからELBの方が処理が複雑であり、性能面でNetwork Load Balancingの方が有利ということは容易に想像できます。また、Network Load BalancingはPre-Warmingなしで100万rps(request per second)に対応できるスケーラビリティも魅力です。
一方で、Network Load BalancingにはSSL Termination機能が無いので、SSL/TLS通信はVMインスタンスのWebサーバーで対応する必要があります。SSL Termination処理をロードバランサにオフロードすることができないため、VMインスタンスに負荷がかかると考えることもできます。
クライアントIPの取得
ELBでは、インスタンスのHTTPの直接の通信相手がロードバランサになるため、WebサーバーのアクセスログにはロードバランサのIPアドレスが記載されていました。そこで、ELBではクライアントIPを通知するためにHTTPヘッダX-Forwarded-Forを付与し、Webサーバー側でそのヘッダをログに記載する必要がありました。Network Load BalancingはクライアントIPが送信元IPとして直接VMインスタンスに届くため、そのような対応は必要ありません。
セッションアフィニティ
ELBではCookieベースのブラウザ単位のセッションアフィニティが利用できますが、Network Load BalancingはIPアドレス/ポートベースのため要件によっては対応が難しい場合も考えられます。ただし、どちらの場合もVMインスタンスの増減や入れ替えがあると転送先が変わることになるため、Webサーバーのインスタンスとは異なるセッションストアなどセッションアフィニティに依存しないセッション管理がベストプラクティスと言えます。
セキュリティ
ELBでは、ロードバランサ用とインスタンス用のファイヤーウォール設定(セキュリティグループ)を区別しインスタンスへの直接の接続はできないようにするといった構成が可能です。Network Load Balancingでは、ロードバランサ用のファイヤーウォール設定は無く、VMインスタンスのファイヤーウォール設定と共通のため、VMインスタンスへの直接の接続のみ制限することはできません。
他の機能との連携
ELBにはEC2インスタンスを自動起動するAuto Scalingと連携して、インスタンスをロードバランサに自動登録する機能があります。Network Load Balancingにも、GCEのAutoscalerと連携する同様の機能があります。
まとめ
GCEのNetwork Load Balancingを触ってみました。雰囲気は伝わったでしょうか?
- Network Load BalancingはL4 DSR型ロードバランサ
- 転送ルール、ターゲットプール、ヘルスチェックを組み合わせて構成する
- VMインスタンスでは、独自の管理サービスでDSRに対応している
HTTP Load Balancingは、また様子の異なるサービスのようなので、引き続き触ってまたレポートしたいと思います!

